

Since the invention of the Transformer architecture, the ability to train large neural networks has advanced greatly, but the science behind it is still in its infancy. The stability of the system appeared in the middle of the shocking and shocking results at the time of the release of Transformers, showing that the performance increases when one increases the number of computers or the size of the network, a phenomenon that is now known as the scaling law. These lifting rules served as a guideline for subsequent scaling studies in deep learning, and the discovery of differences in these rules led to significant increases in performance.
In this paper, he investigates how data quality can be changed in a different way. Higher quality data produces better results; for example, data cleaning is an important part of creating modern databases and can lead to smaller datasets or the ability to run data in iterations. A recent study on TinyStories, a collection of high-quality data that was artificially created to train neural networks in English, showed that the benefits of high-quality data go beyond this. By significantly modifying the loading rules, data manipulation can improve the performance of large models with limited training.
In this study, the authors from Microsoft Research show that good data can improve the SOTA of large-scale models (LLMs) while reducing the size of the dataset and the calculation of studies. The environmental cost of LLMs can be greatly reduced with smaller samples requiring fewer courses. They create custom Python applications from their scripts, using LLMs trained in scripting. HumanEval, the evaluation standard presented in the last paper, has been frequently used to compare LLM performance on codes.
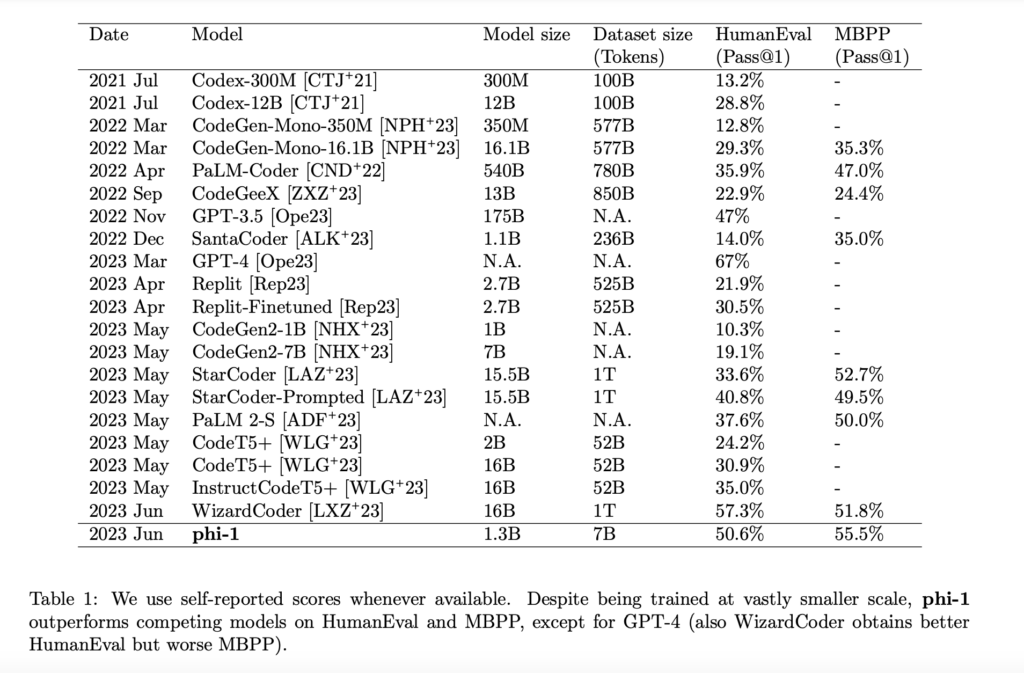
They demonstrate the power of high data by breaking the existing rules by training a 1.3B-parameter model, which they call phi-1, about eight passes 7B tokens (a little over 50B total tokens observed) followed by a small correction . more than 200M tokens. In short, they learn about “book entries”, both professionally designed (with GPT-3.5) and filtered from websites, and they manage “exercise entries”. Although it is several orders of magnitude smaller than the competing models, both in terms of data and sample size (see Table 1), it achieves 50.6% pass@1 accuracy on HumanEval and 55.5% pass@1 accuracy on MBPP (Multiple Python Programming) , which is one of the most self-explanatory codes using only one generation of LLM.
By training the 1.3B-parameter model called phi-1 for eight iterations of more than 7B tokens (more than 50B tokens have been observed), followed by refinement of less than 200M tokens, it shows the potential for high-quality data to be rejected. scaling rules. In most cases, they teach about “textbooks” that are created artificially (using GPT-3.5) and filtered from the Internet, and they improve the “exercise notes”. It achieves 50.6% pass@1 accuracy on HumanEval and 55.5% pass@1 accuracy on MBPP (Mostly Basic Python Programs), which is one of the most self-explanatory numbers using only one generation of LLM, although it is several small programs competing models.
See The Papers. Don’t forget to join Our 25k + ML SubReddit, Discord Channeland Email page, where we share the latest news on AI research, great AI projects, and more. If you have any questions about the article above or if we missed anything, feel free to email us Asif@marktechpost.com
🚀 Check out 100 AI Tools in the AI Tools Club


Aneesh Tickoo is a professional analyst at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. They spend most of their time working on tasks aimed at harnessing the power of machine learning. His research interest is image processing and he likes to create solutions around it. They like to interact with people and participate in interesting activities.
#Microsoft #Research #Launches #Phi1 #Model #LargeScale #Programming #Language #Python #Coding #Smaller #Size #Competing #Models